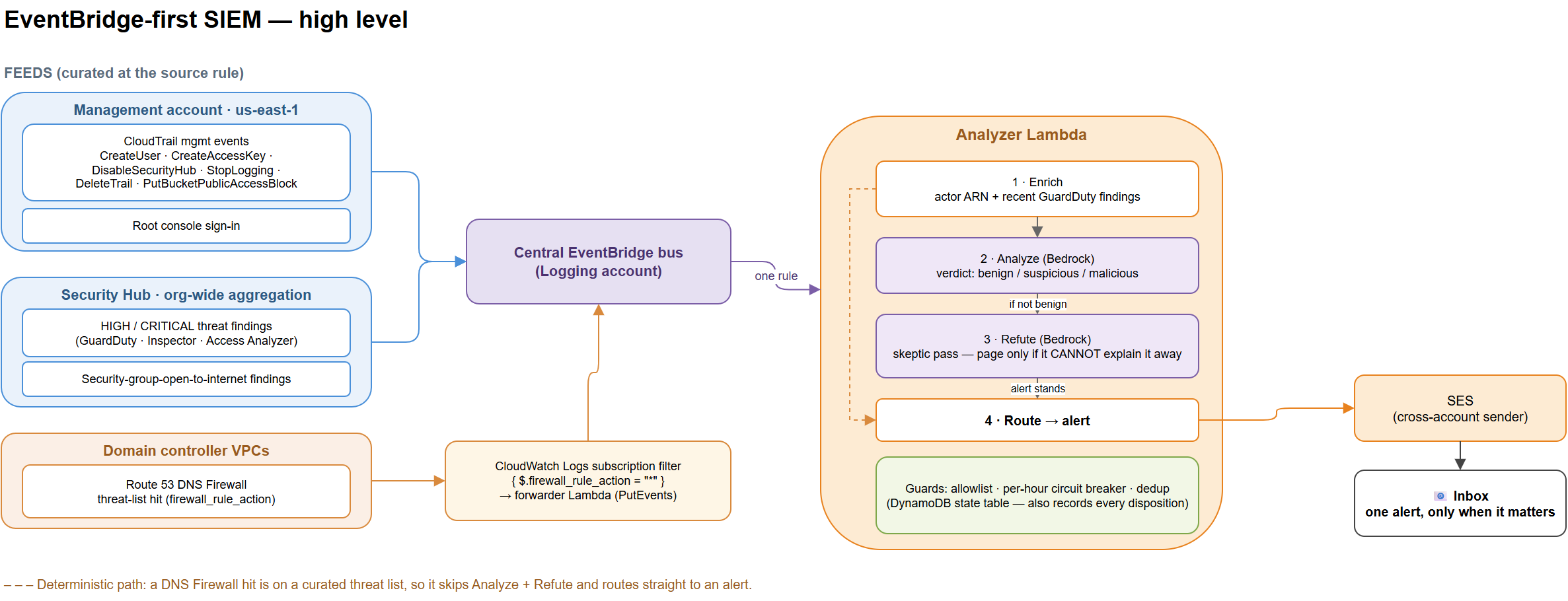
I run a small SIEM for my AWS org, and it is built around one idea: before it pages me, a second model pass tries to refute the first one's alert. It is EventBridge-first. Source accounts forward a curated slice of high-signal events to a central custom bus, one analyzer Lambda triages everything, and SES sends the mail. Five feeds hang off it today: suspicious CloudTrail management calls (access-key creation, policy attaches, security-tool tampering, trail deletion, making a bucket public), root console sign-ins, Security Hub HIGH and CRITICAL threat findings, security-group-open-to-the-world findings, and Route 53 DNS Firewall threat-list hits from my domain controllers. Most feeds run an enrich, then analyze, then refute, then alert pipeline on Bedrock. One feed, the DNS Firewall hits, is deterministically bad and skips the model entirely. This post is the whole thing: the analyze-then-refute design, the cheap guards that keep it from flooding me, the deterministic feed, and how a new log source becomes a feed in about a day.
Why I Built My Own
The catalyst was a security incident I got brought into when my bat phone rang. A domain controller in a data center got pulled into the kind of week where you assume an attacker already has a foothold and start asking what every privileged box is allowed to talk to, and whether you would even notice if one of them did something it shouldn't. The AWS side of the estate extends that same forest, so the question came with it: if a privileged identity or a privileged box in AWS does something hostile, how fast do I find out?
The honest answer at the time was "eventually, if I went looking." Security Hub and GuardDuty were on, but their findings sat in a console I checked when I remembered to. I wanted a thin layer on top that did one job well: watch a small set of genuinely high-signal events across the org, decide which ones are worth waking someone for, and mail me only those. Not a log lake. Not a product with a per-GB bill. A triage brain with opinions.
EventBridge-First, On Purpose
The whole thing is shaped around EventBridge:
- Source accounts forward a curated slice of high-signal events to a central custom event bus in a logging account.
- One rule on that bus sends everything delivered to it to a single analyzer Lambda.
- The analyzer enriches deterministically, runs an optional model pass on Bedrock for the ambiguous events, and alerts via SES.
The reason it is EventBridge and not syslog is the part that saved me the most work. events:PutEvents is a plain public AWS API. Any principal with permission delivers to the bus over the AWS endpoint. No UDP forwarder, no path to an internal load balancer, no cross-region peering, no grok patterns. A syslog SIEM would have started with a week of networking. This started with an IAM policy.
The curation happens at the source, before anything crosses an account boundary. The EventBridge rule pattern is the cheap pre-filter, so the analyzer only ever runs on events that already cleared a bar. Five things clear that bar today:
| Feed | What it catches | How it's triaged |
|---|---|---|
| CloudTrail management calls | Access-key creation, user creation, policy attaches, DisableSecurityHub, StopLogging, trail deletion, flow-log deletion, making a bucket public | Model: analyze then refute |
| Root console sign-in | Anyone logging in as root | Model: analyze then refute |
| Security Hub findings | HIGH and CRITICAL active threat findings from GuardDuty, Inspector, Access Analyzer | Model: triage then refute |
| Security-group exposure | Security groups opened to the internet | Model: triage then refute |
| DNS Firewall threat hits | A domain controller resolving a domain on the AWS-managed threat list | Deterministic: direct alert, no model |
The handler picks the path apart at the top by looking at the event body. A DNS Firewall hit, a Security Hub finding, and a CloudTrail event have different shapes, so adding a feed is a new branch next to ones that already exist, not a rewrite.
Analyze, Then Try to Refute
This is the part I actually care about. A privileged API call is rarely obviously good or obviously bad. CreateAccessKey on a user is routine admin work nine times out of ten and the first move of a credential thief the tenth. A single verdict pass on that is a coin flip dressed up as analysis.
So the model runs twice, in two different roles. The first pass is an analyst: here is the event, here is light enrichment about who did it, decide benign, suspicious, or malicious, with a confidence. If it lands on benign, the event is recorded and nothing else happens.
If it lands on suspicious or malicious, a second pass runs, and its only job is to refute the first one. It is told explicitly that false pages are worse than a missed low-severity event, and to find the benign explanation if one reasonably exists: the legitimate automation, the normal admin workflow, the service principal doing its job. The alert only goes out if the skeptic pass genuinely cannot explain it away.
analysis = analyze(event, enrichment) # benign | suspicious | malicious
if analysis.verdict == "benign":
return # nothing fires
verification = refute(event, analysis) # tries to talk itself down
if not verification.alert_stands:
return # refuted, recorded, no mail
send_alert(...) # survived both passesThe enrichment that feeds the first pass is deterministic and cheap: the actor's ARN pulled out of the event, and the actor's recent GuardDuty findings if any exist. No log dumps go to the model, just the event plus that thin context. Both passes are forced to return a single JSON object, so the routing logic stays boring.
A single "is this bad?" prompt drifts toward alerting, because flagging feels safer to the model than dismissing. Splitting the work into an analyst that proposes and a skeptic that disposes turns that bias into a feature: the first pass can be twitchy, and the second pass is the adult in the room whose whole job is to not wake me up. The events that survive both are the ones worth the interruption.
The Feed That Pages Most: CloudTrail
The management-event feed is the busiest, and it is where the refute pass earns its keep. A good recent example: the SIEM mailed me a CreateUser alert. Real event, real account, and exactly the kind of thing you want eyes on, because user creation in a management account is a classic persistence move.
Except this one was the AWS Identity Center directory sync provisioning an identity-store user from Active Directory, on its normal hourly cadence, from an AWS-internal IP. Same CreateUser event name as a real IAM user creation, different event source entirely (sso-directory.amazonaws.com), and never anything to page on. The forwarder rule had matched on the event name alone, so the sync noise was riding the same rail as the events I care about.
The fix was a one-line tightening of the source rule, excluding that event source so the sync never crosses accounts or reaches the model, plus a matching guard in the analyzer as a backstop. That is the actual texture of running this thing: the design is the easy part, and most of the ongoing work is teaching each feed the difference between its signal and its routine. The good news is that tuning a feed is editing a filter, not rebuilding a pipeline.
The Cheap Guards
A triage brain that can mail me is only safe if it physically cannot run away. Three small guards do that, none of them clever:
- Allowlist. A short list of ARN suffixes for known service principals that are allowed to do alarming-looking things. They short-circuit to recorded-and-ignored before any model call.
- Circuit breaker. An atomic per-hour counter in DynamoDB. Past a cap, the analyzer stops calling the model and just records events. If something goes wrong upstream and the bus floods, the bill and my inbox both stay bounded.
- Dedup. A conditional write to the same state table so the same thing in the same window mails once, not a hundred times.
Everything the analyzer processes, including the events it decides are benign and the ones it suppresses, gets written to the state table. The table is the single source of truth for "what fired and why," which matters the first time someone asks why they did or did not get paged.
The One Feed That Skips the Model: DNS Firewall
Not everything needs a judgment call. After the incident, I restricted egress on the AWS domain controllers and attached a Route 53 Resolver DNS Firewall rule group matching the AWS-managed aggregate threat list (malware, botnet C2, phishing). I ran it in ALERT for a week, saw zero matches, and flipped it to BLOCK with an NXDOMAIN response.
A hit on that list is on a curated threat feed by definition. Asking a model whether a known-malware domain is bad is a way to spend tokens so it can agree with the feed. So this feed routes straight to an alert. The only real work was plumbing, because DNS Firewall writes to CloudWatch Logs and the SIEM reads EventBridge.
The bridge is a CloudWatch Logs subscription filter and a tiny forwarder Lambda. The trick that makes it nearly free is the filter pattern. A DNS Firewall log entry only carries a firewall_rule_action field when the query actually matched a rule, so testing for the field's presence isolates exactly the hits and ignores the firehose of normal lookups:
{ $.firewall_rule_action = "*" }A subscription filter that matches nothing invokes nothing, so on a quiet week this costs effectively zero. The forwarder decodes the gzipped, base64-encoded subscription payload, keeps only the matches, and re-emits each onto the central bus with PutEvents. Its dedup is per host, per domain, per hour, so a box beaconing to a C2 domain every few seconds gives me one email that says "this is happening" instead of four hundred that say it.
Filter at the subscription, not in code. If I had subscribed broadly and filtered inside the Lambda, I would be paying to invoke a function on every DNS query a domain controller makes. The subscription filter, not the Lambda, is the cost control. That principle carries to every other log source you bolt on.
Proving It End to End
Zero real hits is great for security and useless for testing, and the same is true of most of the alarming events the other feeds watch for. You do not want to wait for a real incident to learn that SES delivery was misconfigured. So I test with synthetic events: a hand-built payload shaped exactly like the real thing, fired straight at the entry point, with an obviously fake value so the alert reads as a test.
It flows the whole way: forwarder decodes and calls PutEvents, the bus rule routes to the analyzer, the analyzer hits the right branch, writes its records to DynamoDB, and sends the email. The test lands in my inbox a couple of minutes later. That confirms every hop including SES, which is the one piece you cannot verify by reading logs.
The test writes a real dedup key and sends a real email. Use an obviously fake value, and remember the dedup key now exists, so a second identical test in the same hour gets suppressed, not because anything is broken but because dedup is doing its job.
Adding the Next Feed
The reason this was worth building once is that every feed after the first is cheap. The DNS Firewall forwarder is a generic CloudWatch-Logs-to-EventBridge bridge that knows nothing about DNS. Point a subscription filter at any log group, map a couple of fields onto an event, add a branch in the analyzer, and that source is in the SIEM:
| Log source | Filter to the signal | What the SIEM gets |
|---|---|---|
| VPC Flow Logs | REJECT records to or from suspicious ranges | Blocked egress and east-west attempts |
| WAF logs | action = BLOCK |
Web attacks stopped at the edge |
| Application logs | Auth failures, 5xx bursts, the strings you dread | App-layer signals next to infra ones |
Deploy the filter and forwarder as a StackSet and every account onboards the same way. The expensive part, an event-driven SIEM that already knows how to receive, enrich, judge, and route, you build once. After that, every log group in the landscape is one filter away from being a detection.
DNS Firewall was a gift because firewall_rule_action only exists on a match. Other sources are not that polite. VPC Flow Logs and app logs are high-volume, so the filter pattern is doing real work. Keep it tight, and resist the urge to forward everything and sort it out later.
What I'd Tell Someone Building This
| Lesson | Why it matters |
|---|---|
| Split the model into propose and dispose | One verdict pass drifts toward alerting; a skeptic pass whose only job is to refute is what keeps the false-page rate livable |
| Curate at the source rule, not in the Lambda | The EventBridge pattern is the cheap pre-filter; the analyzer should only ever see events that already cleared a bar |
| Most ongoing work is tuning a feed, not building one | A CreateUser from a directory sync looks identical to a real one until you filter on event source; expect to teach each feed its own noise |
| Guard against your own runaway | An allowlist, a per-hour circuit breaker, and dedup keep a bad upstream day from flooding your bill and your inbox |
PutEvents is a public API |
No VPC, syslog, or cross-region path to an internal endpoint, unlike a syslog SIEM |
| Not every event needs a model | A threat-list hit is deterministically bad; skip the model and save the tokens and latency |
| Test with synthetic events | Zero real matches is the healthy state, so you have to fake one to prove the wiring and SES delivery |
The SIEM is deliberately small: a central bus, a few forwarders, one analyzer Lambda, a DynamoDB table for state, and SES for the mail. What makes it useful is not size, it is that it has an opinion. It enriches before it judges, it argues with itself before it pages, and it would rather stay quiet than cry wolf. The domain controllers were just the first thing I pointed it at. The forest was always hybrid, spread across a data center, AWS, and Azure under one identity. The detection layer is finally catching up to it, one feed at a time.
Want Help With This?
If you're working on something similar and want a second set of eyes, or you'd like to talk through how this applies to your environment, reach out via the contact form. Happy to help.