I built a Step Functions pipeline that patches a hardened Amazon Linux 2023 golden AMI on the 1st of every month with zero manual work. It launches a temporary instance from the current golden AMI, runs the OS update via an SSM Automation document, snapshots a new AMI, re-encrypts it with a dedicated org-wide KMS key, shares it across the entire AWS Organization, and writes the new AMI ID to a shared SSM parameter. Consumers that reference that parameter pick up the patched image on their next deploy. The two design decisions that made it clean: a dedicated KMS key with an org-scoped policy (instead of touching the account-managed EBS key), and an SSM parameter shared via RAM so consumer accounts auto-resolve the latest AMI by ARN.
The Problem
Every EC2 instance across the organization needs to boot from a hardened, patched operating system. Letting teams pick whatever AMI they find means stale kernels and drifted baselines within a quarter. The usual answer is a golden AMI: one locked-down image everyone builds on. The catch is that a golden AMI is only golden the day you bake it. A month later it's missing a month of OS patches.
So the real requirement isn't "make a golden AMI," it's "keep the golden AMI fresh forever without a human in the loop." That's a patching pipeline, and a state machine is a good fit because the work is a linear sequence of long-running AWS calls where any step can fail and you want a clean failure path.
What the Pipeline Does Each Month
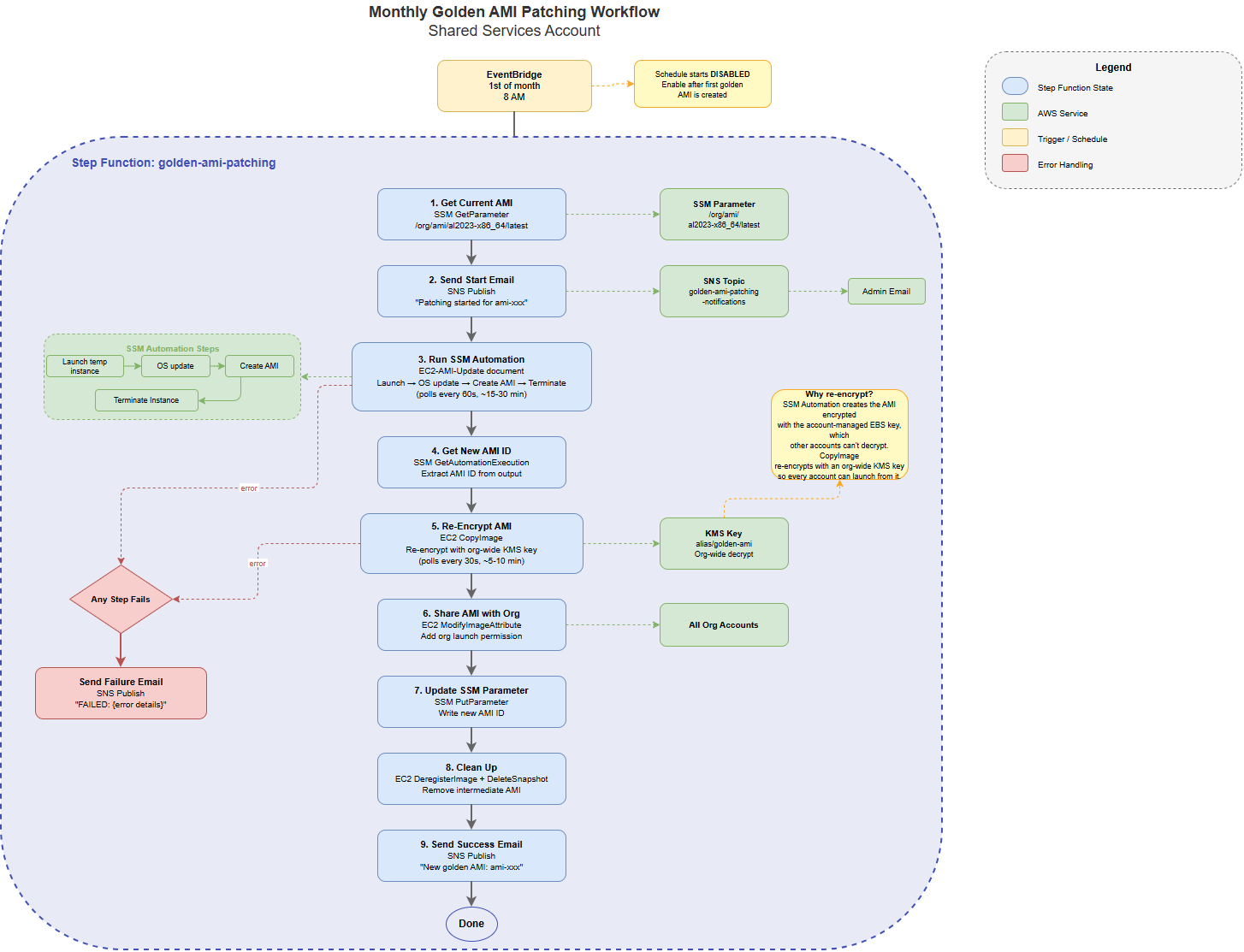
An EventBridge schedule fires on the 1st at 8 AM and starts the state machine. From there:
- Read the current AMI. Pull the existing golden AMI ID from an SSM parameter.
- Notify start. Send an SNS email so admins know a run is in flight.
- Patch. Kick off an SSM Automation document that launches a temp instance from the current AMI, runs the OS update, stops it, and snapshots a fresh AMI.
- Re-encrypt. Copy the new AMI, re-encrypting it with a dedicated org-wide KMS key.
- Share. Add the whole Organization as a launch permission on the copy.
- Publish. Overwrite the SSM parameter with the new AMI ID.
- Clean up. Deregister the intermediate AMI and delete its snapshot.
- Notify success (or failure, from any step).
End to end it runs about 25 to 40 minutes, almost all of which is the patch-and-snapshot step. The state machine polls that step on an interval rather than blocking.
Why a Separate KMS Key Instead of the Default EBS Key
This is the part that trips people up and the part I'd most want a teammate to understand.
In a Landing Zone style org, each account has its own account-managed EBS encryption key. When the shared services account bakes an AMI, the snapshot lands encrypted under that account's key. Other accounts in the org cannot decrypt it, so they cannot launch from it. The AMI is shared but useless.
The tempting fix is to widen the account-managed EBS key policy to allow org-wide decrypt. Don't. That key is managed by the landing zone and protects every encrypted volume in the account. Editing its policy to grant cross-account decrypt is a broad blast radius for a narrow need.
Create one dedicated KMS key whose only job is golden AMI encryption. Its key policy grants kms:Decrypt and kms:DescribeKey to the entire Organization via an aws:PrincipalOrgID condition. Then have the pipeline copy the freshly baked AMI, re-encrypting it under this key. Isolated purpose, isolated blast radius, and you never touch the landing zone's key.
That copy step is why the pipeline produces two AMIs and throws one away. The first (baked by the SSM Automation) is encrypted under the account-managed key. The second (the re-encrypted copy) is the one that gets shared. The first is deregistered in the cleanup step so you're not paying for snapshots nobody can use.
The CreateGrant Gotcha on Consumers
Granting kms:Decrypt and kms:DescribeKey to the org on the key policy is necessary but not sufficient. When EC2 launches an instance from an AMI encrypted with a customer-managed key, it needs to create a grant on that key. kms:CreateGrant has to be on the caller's IAM policy, not just the key policy.
If a consumer account tries to launch from the golden AMI and the instance role is missing kms:CreateGrant on the golden AMI key, you get a launch failure that points at the KMS key state rather than at permissions, which sends people down the wrong rabbit hole.
The instance role almost certainly lacks kms:CreateGrant on the golden AMI KMS key. Add kms:CreateGrant, kms:Decrypt, and kms:DescribeKey scoped to the golden AMI key ARN on the launching role. The key policy alone does not cover the grant the launch needs.
Distributing the AMI ID via a Shared SSM Parameter
Sharing the AMI org-wide solves "can accounts see and launch it." It doesn't solve "how does a template know the current AMI ID without someone editing it every month."
The answer is an SSM parameter holding the latest AMI ID, shared to every account via AWS RAM. CloudFormation can resolve an SSM parameter at deploy time, so a template that references the parameter picks up the newest AMI on its next deploy with no edit.
Parameters:
GoldenAmiId:
Type: AWS::SSM::Parameter::Value<String>
Default: arn:aws:ssm:us-east-2:111111111111:parameter/org/ami/al2023-x86_64/latestThe parameter lives in the shared services account and reaches consumers through RAM. A consumer in another account has to reference it by full ARN (arn:aws:ssm:region:account:parameter/path), not by the short name. The short name only works inside the account that owns the parameter.
For the cases where SSM parameter resolution isn't available (StackSets, for example), the fallback is hardcoding the AMI ID in a mapping and updating it after each monthly run. It works, but it's the manual path, so I keep it to the templates that genuinely can't resolve the parameter.
Why the Patch Step Is an SSM Automation Document, Not Inline Logic
The actual bake (launch temp instance, wait for SSM registration, run the OS update, stop, snapshot, terminate) lives in an SSM Automation document deployed to every account, not inside the state machine. The state machine just starts the automation and polls for completion.
Keeping the bake in a reusable automation document means the same patching primitive is available to any account that wants to bake its own image, and the state machine stays focused on orchestration, encryption, sharing, and notification. It also keeps the long-running compute work out of the state machine's own execution, which only needs to poll.
What's Actually in the Hardened Base
The patching pipeline keeps the image fresh, but the image itself is hardened at bake time by a separate provisioning script. The controls on the AL2023 base, aligned to NIST 800-171:
| Area | What's applied |
|---|---|
| OS patches | Full update at bake, refreshed monthly by the pipeline |
| SELinux | Enforcing |
| SSH | Key-only, no root login, restricted ciphers |
| Auditing | auditd rule set aligned to the control baseline |
| File integrity | AIDE installed and initialized |
| Kernel / network | sysctl hardening, unnecessary services disabled |
| Observability | CloudWatch agent pre-installed |
The golden AMI is a base, not a finished server. App teams add their own packages in launch template UserData on top of it. That keeps the image small and the hardening generic.
Failure Handling and Operability
Every state routes its error path to a single failure-notification step that emails the admins with the failing step and the error. There's no silent partial run. Because the pipeline replaces the SSM parameter only as the second-to-last step, a failure before that point leaves the existing golden AMI ID in place. Consumers keep resolving last month's known-good image until a run fully succeeds.
If a monthly patch breaks something downstream, SSM parameter consumers don't break immediately because they only re-resolve on their next deploy. A team that needs to buy time can pin to the previous AMI ID, troubleshoot, then switch back to the parameter once they've confirmed the new image is fine. No emergency pipeline surgery required.
Lessons Worth Carrying Forward
- Don't widen the landing zone's EBS key. A dedicated, single-purpose KMS key with an org-scoped policy is the right blast radius for cross-account AMI sharing.
- The key policy doesn't cover the launch grant. Consumers need
kms:CreateGranton their own IAM role, or launches fail with a misleading KMS-state error. - Share the AMI ID, not just the AMI. An SSM parameter shared via RAM turns "edit every template monthly" into "deploy normally."
- Full ARN for cross-account SSM. The short parameter name only resolves in the owning account.
- Update the pointer last. Writing the SSM parameter near the end of the run means any earlier failure leaves the previous known-good AMI in service.
Want Help With This?
If you're working on something similar and want a second set of eyes, or you'd like to talk through how this applies to your environment, reach out via the contact form. Happy to help.